
Los buscadores tienen limitaciones al rastrear la web e interpretar el contenido para mostrar los resultados. En esta sección de la guía nos centraremos en los aspectos técnicos específicos de la creación (o modificación) de páginas web para que estén perfectamente estructuradas para los buscadores y visitantes. Esta parte de la guía es excelente para compartir con tus programadores, arquitectos de información y diseñadores, para que todos los que forman parte de la construcción del sitio puedan idear y desarrollar un sitio web optimizado para motores de búsqueda.

CONTENIDO INDEXABLE
A fin de aparecer en los buscadores, tu contenido – el material disponible para los visitantes de tu sitio – debe estar en formato de texto HTML. Las imágenes, archivos Flash, applets de Java y otros contenidos sin texto son prácticamente invisibles para los robots de los buscadores, a pesar de los avances en la tecnología de rastreo. La manera más fácil de asegurarte de que las palabras y frases que muestras a los visitantes son también visibles para los buscadores es colocándolas en el texto HTML de tu página. Sin embargo, existen métodos más avanzados para aquellos que requieren más formatos y estilos visuales:
1. Las imágenes en formato gif, jpg o png pueden ser asignadas como «atributos alt» en HTML, proporcionando a los buscadores una descripción en texto del contenido visual.
2. También se pueden mostrar imágenes a los visitantes en vez de texto usando estilos CCS.
3. Los contenidos en Flash o Plug-in de Java se pueden repetir con texto en la página.
4. Los contenidos de video y audio deberían estar acompañados de una transcripción si queremos que los buscadores indexen las palabras o frases que usan.
VIENDO COMO VE UN BUSCADOR
Muchas webs tienen problemas con la indexación de su contenido, por lo que merece la pena revisarlas. Usando herramientas como la caché Google, SEO-browser.com o mozBarpuedes ver qué elementos de tu contenido son visibles e indexables para los buscadores. Mira la versión de texto en la cache de Google de esta misma página. ¿Ves la diferencia?
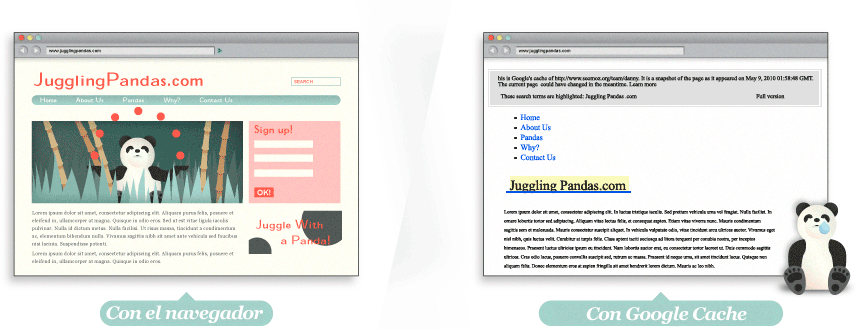
INCREÍBLE! ¿ASÍ ES COMO NOS VEN?
Usando las características de la caché de Google, podemos ver que para un buscador, la página principal de pandasmalabaristas.com no contiene toda la detallada información que nosotros vemos. Eso es grave porque se les hace difícil interpretar la relevancia.

¿HAY UN MONTÓN DE MONOS, Y SOLO TEXTO EN EL TÍTULO?
¡HEY! ¿A DÓNDE SE HA IDO LA DIVERSIÓN?
A través de la caché de Google, podemos ver que la página es un desierto árido. Ni siquiera hay texto que nos diga que la página contiene monos que luchan con hachas. El sitio entero está construido en Flash, pero, infelizmente, esto significa que los buscadores no pueden indexar ningún contenido, ni siquiera los enlaces a los juegos individuales. Sin texto en formato HTML esta página tendrá muchos problemas para obtener rankings en los buscadores.
Sería prudente no mirar solo el contenido en texto sino también usar herramientas SEO para verificar que las páginas que estés creando sean visibles para los buscadores. Eso aplica también a las imágenes y enlaces de tu sitio.
ESTRUCTURAS DE ENLACES INDEXABLES
Los buscadores necesitan ver contenido para incluir las páginas en sus enormes índices de palabras clave. También necesitan tener acceso a una estructura de enlaces rastreable – una que permita a sus robots rastrear los caminos del sitio web – para encontrar todas las páginas del sitio web. Cientos de miles de sitios cometen el grave error de esconder u ofuscar su navegación de manera que los buscadores no pueden acceder, y por lo tanto, repercuten en su capacidad para incluir las páginas en su índex de búsqueda. Más abajo se muestra cómo puede suceder este problema:
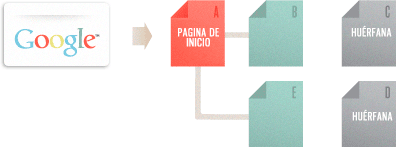

En el ejemplo de arriba, el robot de rastreo de Google ha llegado a la página “A” y ve los enlaces a las páginas “B” y “E”. Sin embargo, a pesar de que C y D pudieran ser páginas importantes del sitio web, el robot no tiene manera de llegar a ellas (o siquiera saber que existen) porque no hay un enlace directo rastreable que lo dirija a esas páginas. Por lo que a Google respecta, puede que tampoco existan – buen contenido, buen enfoque en las palabras clave, y un marketing apropiado no serviría de nada si primero los robots de rastreo no pueden llegar a esas páginas.
ANATOMÍA DE UN ENLACE

En la ilustración de arriba, el tag » cierra en enlace, para que no aplique a otros elementos que siguen en la página.
Este es el formato de enlace más básico – y los buscadores lo entienden perfectamente. Los robots saben que deben añadir este enlace al “link graph” del buscador, usarlo para calcular variables de consultas independientes (como el PageRank de Google) y seguirlo hasta el índex de contenidos de la página a la que hace referencia.
VEAMOS ALGUNAS DE LAS RAZONES MÁS COMUNES POR LAS QUE NO SE PUEDE ACCEDER A LAS PÁGINAS
ENLACES EN FORMULARIOS DE REGISTRO
Los formularios pueden contener algo tan sencillo como un menú desplegable o tan complejo como una encuesta en toda regla. En cualquier caso, los robots rastreadores no podrán “completar” formularios y, por tanto, cualquier contenido o enlace que sea accesible vía formulario será invisible para los buscadores.
ENLACES EN JAVASCRIPT
Si usas JavaScript para los enlaces, te habrás dado cuenta de que, o los buscadores no los rastrean, o no dan mucha importancia a los enlaces incrustados dentro de ellos. Los enlaces en JavaScript deberían ser reemplazados (o acompañados) por enlaces normales en HTML en cualquier página que desees que los robots rastreen.
ENLACES QUE APUNTAN A PÁGINAS BLOQUEADAS POR “META TAGS ROBOT” O ROBOTS.TXT
Los meta tags robot y robot.txt (descripción completa aquí) permiten al dueño de un sitio restringir el acceso de un robot a la página. Pero cuidado, muchos webmasters han intentado usarlas para bloquear el acceso a robots maliciosos, y han descubierto que los buscadores han dejado de rastrear también.
ENLACES EN FRAMES O I-FRAMES
Técnicamente, tanto los enlaces en frames como en I-frames son rastreables, pero ambos presentan problemas estructurales para los buscadores en cuanto a organización y seguimiento. A menos que seas un usuario avanzado con bastantes conocimientos técnicos sobre la manera en que los buscadores indexan y siguen los enlaces en frames, es mejor alejarse de ellos.
ENLACES ACCESIBLES ÚNICAMENTE MEDIANTE UNA CONSULTA
Aunque está directamente relacionado con la advertencia anterior sobre los formularios, suele ser un problema tan común que merece la pena mencionarlo. Los robots no intentarán realizar búsquedas para encontrar contenido, y por ello, se estima que millones de páginas están escondidas tras muros completamente inaccesibles, condenadas al anonimato hasta que una página indexada las enlace.
ENLACES EN FLASH, JAVA, U OTROS PLUG-INS
Los enlaces incrustados en el sitio web del Panda (de nuestro ejemplo anterior) ilustran perfectamente este fenómeno. Aunque hay decenas de pandas listados y enlazados en la página del Panda, ningún robot puede llegar a ellos debido a la estructura de enlaces del sitio, volviéndolos invisibles para los buscadores (e imposibles de encontrar por los usuarios que realicen consultas).
ENLACES EN PÁGINAS CON CIENTOS DE MILES DE ENLACES
Los buscadores tienden a rastrear una cantidad definida de enlaces por página, no todos los que encuentren hasta el infinito. Páginas con cientos de enlaces en ellas corren el riesgo de que no todos esos enlaces se indexen.
REL=NOFOLLOW
Rel=”nofollow” puede usarse con la siguiente sintaxis:

Se pueden aplicar muchos atributos a los enlaces, pero los buscadores los ignoran casi todos, con la importante excepción del tag rel=”nofollow”. En el ejemplo de arriba, al añadir el atributo rel=nofollow al tag, le decimos a los buscadores que nosotros, los propietarios del sitio, no deseamos que ese enlace se interprete como se haría normalmente. Nofollow surgió como un método para detener comentarios automatizados en blogs, libros de visitas, e inyección de spam (lee más sobre el tema aquí), pero a lo largo del tiempo se ha ido transformando en una manera de decir a los buscadores que ignoren cualquier valor de enlace que transmitirían normalmente. Los enlaces etiquetados como nofollow se interpretan de forma ligeramente diferente en cada buscador, pero es un hecho que no transmiten tanto valor como los enlaces normales.
SON MALOS LOS ENLACES NOFOLLOW?
A pesar de que no transmiten valor, a diferencia de los enlaces normales (dofollow), los enlaces nofollow forman parte de cualquier perfil normal de enlaces de una web. Una web con cientos de enlaces entrantes acumulará varios links nofollow, lo cual no es malo. De hecho, las páginas que ostentan buenos rankings en los buscadores tienden a tener un mayor porcentaje de links nofollow que aquellas con rankings menores.
USO DE PALABRAS CLAVE Y TARGETTING
Las palabras clave son fundamentales para el proceso de búsqueda – son los pilares del lenguaje y las búsquedas. De hecho, toda la ciencia de recuperación de información (incluyendo a los buscadores como Google) se basa en las palabras clave. Como los buscadores rastrean e indexan los contenidos de las páginas de toda la web, mantienen registros de esas páginas en índices según las palabras clave. Por eso, en vez de almacenar 25 mil millones de páginas web en una sola base de datos (que sería bastante grande), los buscadores tienen millones y millones de bases de datos más pequeñas, las cuales se centran en una sola palabra clave o frase. Esto hace que los buscadores puedan recuperar la información que necesitan mucho más rápido, apenas en una fracción de segundo.
Obviamente, si quieres que tu página tenga una oportunidad de aparecer en los resultados de búsqueda para la palabra “perro”, sería muy recomendable que te asegures de que la palabra “perro” sea parte del contenido indexable de tu documento.
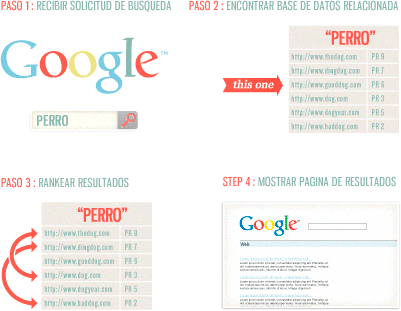

DOMINIO DE LAS PALABRAS CLAVE
Las palabras clave también influyen profundamente en nuestra manera de buscar e interactuar con los buscadores. Por ejemplo, un patrón de búsqueda común pudiera ser tal como sigue:
Cuando se realiza una búsqueda, el buscador sabe qué páginas debe recuperar según las palabras escritas en la casilla de búsqueda. Otros datos como el orden de las palabras («disparo de tanques» en vez de «tanques disparando»), ortografía, puntuación, uso de mayúsculas, brindan información adicional que los buscadores pueden usar para facilitar la recuperación de las páginas correctas y clasificarlas.
Por razones obvias, los buscadores tienen en cuenta la manera en que se usan las palabras clave para determinar más fácilmente la “relevancia” de un documento en una consulta. Una de las mejores maneras de “optimizar” el ranking de una página, es, por tanto, asegurarse de destacar las palabras clave en los títulos, texto y meta datos.
La imagen del mapa de la izquierda muestra la relevancia del término “Books” (libros) en relación al título, “Tale of two cities” (Historia de dos ciudades). Nótese que mientras hay un montón de resultados (el tamaño del país) para el término general, hay muchos menos resultados y por tanto mucha menos competencia para el resultado específico.
ABUSO DE KEYWORDS
Desde el nacimiento de las búsquedas, las personas han abusado del uso de las keywords de forma negativa buscando manipular a los motores de búsqueda. Esto consiste en rellenar de keywords los textos, las URLs, metatags y enlaces. Estas tácticas crean más daños que beneficios a tu web.
Al inicio, los buscadores confiaban en las keywords como un signo importante de relevancia, sin importarles cómo eran estas usadas. Ahora, a pesar de que los buscadores aún no pueden leer y comprender textos tan bien como lo hace un humano, el uso de máquinas inteligentes los ha acercado a este ideal.
Lo mejor que puedes hacer es utilizar tus keywords de forma natural y estratégica. Si tu página se enfoca en la palabra clave «Machu Picchu» entonces podrías incluir de forma natural contenido relacionado a Machu Picchu, su historia, o incluso recomendar hoteles en Machu Picchu. Por otro lado, si simplemente agregas la palabra «Machu Picchu» en una página que en realidad se centra en otro tema, como una página sobre crianza de perros, entonces tendrás un duro camino para llegar a rankear para dicho término.
EL MITO DE LA DENSIDAD DE PALABRAS CLAVE
La densidad de palabras clave no forma parte de los algoritmos modernos de rankings, como lo demostró el Dr. Edel Garcia en «The Keyword Density of Non-sense» (El sinsentido de la densidad de palabras clave).
En este estudio se concluye que la densidad de palabras clave no incluye conceptos como contenido, calidad del contenido, y relevancia.
Entonces, ¿cómo debería verse una página con una densidad apropiada?
Una página apropiada para la frase “zapatillas” debería por lo tanto verse de esta manera:

OPTIMIZACIÓN ON-PAGE
Con todo, el uso de palabras clave y su enfoque son solo una pequeña parte de los algoritmos de clasificación de los motores de búsqueda, y todavía podemos sacar algunas “buenas prácticas” que sean efectivas en el uso de palabras clave para facilitar la creación de páginas que estén casi “optimizadas”. En Moz se realizan muchas pruebas y llegamos a ver un gran número de resultados de búsqueda y cambios basados en las tácticas relacionadas con el uso de palabras clave. Cuando trabajes con uno de tus propios sitios web, te recomendamos este proceso:
– Usa la palabra clave en el tag de título al menos una vez, dos si es posible (o como variante) y si tiene sentido y suena bien (esto es subjetivo, pero necesario). Intenta mantener la palabra clave tan cerca del principio del título como puedas. Más adelante en esta sección se verán detalles sobre los tags de título.
– Una vez en el tag de encabezamiento H1 de la página.
– Al menos tres veces en la copia del cuerpo de la página (a veces incluso algunas veces más si es que hay bastante contenido en forma de texto). Podríamos pensar que sería mejor usarla más de tres veces, pero según nuestra experiencia, añadir el término o la frase más veces suele tener poca o ninguna influencia en los rankings.
– Al menos una vez en el “atributo alt” de una imagen en la página. Esto no solo ayuda con las búsquedas web, sino también con la búsqueda de imágenes, que de vez en cuando pueden atraer algo de tráfico.
– Una vez en la URL. Más adelante en esta sección se explicarán más reglas sobre las URL y las palabras clave.
– Al menos una vez (o dos si tiene sentido) en el “meta tag description”. Note que los buscadores NO usan el “meta tag description” para los rankings, sino que ayuda más bien a atraer clics de los usuarios en la página de resultados de búsqueda (ya que es el “fragmento” del texto que usan los buscadores).
– Por regla general, no se usa en el “anchor text” de enlaces que apunten a otras páginas de tu mismo sitio o a diferentes dominios
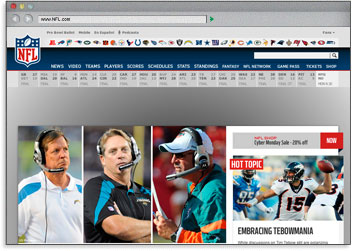
El tag de título de cualquier página aparece en la parte superior del software usado para navegar por Internet, y suele ser usado como título cuando tu contenido es compartido o republicado en redes sociales.
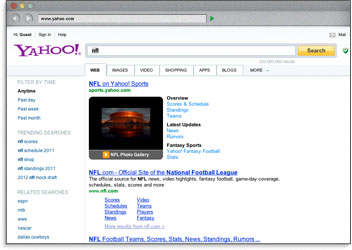
Usar palabras clave en el tag de título implica que los buscadores resalten esas palabras en negrita en los resultados de búsqueda cuando un usuario realice una búsqueda con esos términos. Esto ayuda a ganar mucha más visibilidad y una mayor proporción de clics.
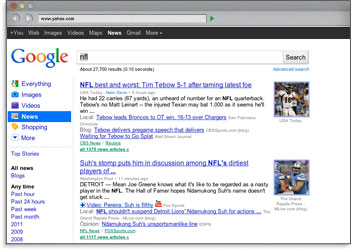
La razón final y más importante para crear títulos descriptivos y con keywords es para mejorar los rankings en los buscadores. Nuestras investigaciones indican que el 94 % de usuarios considera que el tag de título es el mejor lugar para colocar keywords y obtener buenos resultados.
TAGS DE TÍTULO
El elemento de título de una página debe ser preciso, una descripción concisa del contenido de la página. Aumenta el valor en tres campos específicos (véanse a la izquierda) y es crucial tanto para la experiencia del usuario como para la optimización para motores de búsqueda.
Ya que los tags de título son una parte tan importante de la optimización para motores de búsqueda, sigue las buenas prácticas en cuanto a los tags de título y producirás tremendos frutos, fáciles de obtener. Las recomendaciones que siguen abarcan las partes más cruciales a la hora de optimizar los tags de título para motores de búsqueda y objetivos de usabilidad:
SÉ CONSCIENTE DEL TAMAÑO
El tamaño máximo que se muestra en los resultados de búsqueda es de 70 caracteres (los buscadores mostrarán puntos suspensivos – “…” para indicar cuando un tag de título ha sido recortado), y sería prudente ajustarse a esos límites. No obstante, si estás apuntando a varias palabras clave (o a una frase especialmente larga) que necesitas para posicionarte, es recomendable hacerla más larga.
PON LAS PALABRAS CLAVE IMPORTANTES CERCA DEL PRINCIPIO
Cuanto más cerca estén la palabras clave del inicio del tag de título, más útiles serán para posicionarse y más probable será que alguien haga clic en ellas en los resultados de búsqueda (al menos según las pruebas y experiencia de Moz).
INFLUENCIA DE LA MARCA
En Moz, les encanta empezar cada pequeño tag haciendo mención de la marca, ya que esto ayuda a dar a conocer la marca, y a generar un ratio de conversión mayor entre las personas a las que les gusta una marca y están familiarizadas con ella. Sin embargo, muchas empresas SEO recomiendan usar el nombre de la marca al final del tag de título, y a veces ese puede ser un método mejor – piensa en lo que más le conviene tu sitio web (o al de tu cliente) y cuán influyente es la marca.
TEN EN CUENTA QUE SEA FÁCIL DE LEER Y QUE TENGA IMPACTO EMOCIONAL
Crear un tag de título atrayente resultará en más visitas desde los resultados de búsqueda y ayudaría a atraer visitantes hacia tu sitio web. Por eso, no solo es importante pensar en la optimización y el uso de palabras clave, sino en la experiencia de usuario en general. El tag de título es el primer contacto entre un nuevo visitante y tu marca, y debería transmitir la mejor impresión posible.
META TAGS
META ROBOTS
Los meta tags ROBOTS pueden servir para controlar la actividad de los robots de rastreo de los buscadores (de la mayoría de los buscadores más importantes) a nivel de página. Hay muchas maneras de usar meta robots para controlar la manera en que los buscadores tratan una página:
Index/NoIndex dice a los buscadores si la página debería ser rastreada y guardada por el Index del buscador para su recuperación. Si te decides por usar “noindex”, los buscadores excluirán esa página. Por defecto, los buscadores dan por sentado que pueden indexar todas las páginas, así que por regla general es innecesario usar el valor “index”.
Follow/NoFollow dice a los buscadores si la página debería ser rastreada. Si decides usar “nofollow”, los buscadores harán caso omiso de los enlaces en la página, tanto para propósitos de exploración como de clasificación. Por defecto, todas las páginas cuentan con el atributo “follow”.
Noarchive se usa para que los buscadores que no guarden una copia de la caché de la página. Por defecto, los buscadores mantendrán una copia visible de todas las páginas indexadas, accesibles para los usuarios a través del “enlace caché” en los resultados de búsqueda.
Nosnippet informa a los buscadores que deberían abstenerse de mostrar un bloque de texto informativo al costado del título de la página y la URL en los resultados de búsqueda.
NoODP / NoYDir son tags especializados que dicen a los buscadores que no muestren la descripción del Open Directoy Project (DMOZ) o la del directorio de Yahoo!, respectivamente, en los resultados de búsqueda.
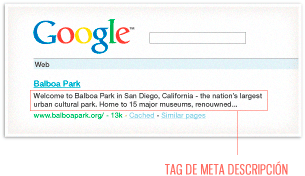
META DESCRIPTION
El tag meta description funciona como una breve descripción del contenido de una página. Los buscadores no usan las palabras clave o frases para los rankings, pero la descripción es la primera fuente a la que acuden en busca de un fragmento del texto mostrado bajo la lista en los resultados.
El tag meta descripción hace la función de copia de publicidad, atrayendo lectores a tu sitio web desde los resultados y, por tanto, es una gran faceta del marketing en buscadores. Crear una descripción fácil de leer y atrayente usando palabras clave (nótese la manera como Google resalta en “negrita” las palabras buscadas en la descripción) puede generar un ratio de conversión mucho mayor de usuarios a tu página web.
Las meta descripciones pueden ser de cualquier tamaño, pero normalmente los buscadores cortarán fragmentos mayores que 160 caracteres (como en el ejemplo del Parque Balboa a la derecha), así que es prudente ceñirse a esos límites.
META TAGS NO TAN IMPORTANTES
META KEYWORDS
El meta tag keywords tenía valor antiguamente, pero ahora ya no tiene valor alguno en la optimización para motores de búsqueda. Para más información sobre la historia y un relato completo del porqué meta keywords ha caído en desuso, lee Meta Keywords Tag 101 de SearchEngineLand.
META REFRESH, META REVISIT-AFTER, META CONTENT TYPE, ETC.
Aunque estos tags pueden usarse en la optimización para motores de búsqueda, son menos cruciales para el proceso, y por ello se los dejo a Google Webmasters para que los explique con mayor detalle – Los Meta Tags y las Búsquedas Web.
ESTRUCTURAS URL

Ya que los buscadores presentan a las URLs en sus resultados de búsqueda, pueden impactar en la visibilidad y en los clics recibidos. Las URLs se utilizan también para definir los rankings, y aquellas páginas cuyas URLs incluyen el término buscado, reciben mayores beneficios por un uso adecuado de keywords.

Las URL aparecen en la barra de direcciones del navegador, y aunque suele influir poco en los buscadores, una mala estructura o diseño de URL puede conllevar una mala experiencia de usuario.
La URL en esta imagen esta siendo usada como anchor text, apuntando a una página de referencia que el blog de la imagen esta utilizando.
PAUTAS PARA LA CONSTRUCCIÓN DE URLS
USA LA EMPATÍA
Ponte en la mente del usuario y mira tu URL. Si eres capaz de prever el contenido que esperas encontrar en la página con facilidad y exactitud, significa que tus URL son adecuadamente descriptivas. No necesitas explicar cada detalle en la URL, pero es bueno empezar con una idea básica.
CUANTO MÁS CORTO, MEJOR
Si bien es importante tener una URL descriptiva, minimizar el tamaño y el reguero de barras hará que tu URL sea más fácil de copiar y pegar (en e-mails, blogs, mensajes de texto, etc.) y se podrá ver entera en los resultados de búsqueda.
EL USO DE PALABRAS CLAVE ES IMPORTANTE (EN EXCESO ES PELIGROSO)
Si tu página se centra en una palabra clave o en una frase, asegúrate de incluirla en la URL. En cualquier caso, no la sobrecargues intentando llenarla de varias palabras clave con intención de hacer SEO – el uso excesivo implica URLs menos usables y puede activar los filtros de spam (de los e-mails, de los clientes, de los buscadores, ¡e incluso de la gente!)
HAZTE ESTÁTICO
Con tecnologías como las de mod_rewrite para Apache e ISAPI_rewrite para Microsoft, no hay excusa para crear URLs sencillas y estáticas.
En una URL, Incluso algunos parámetros dinámicos por sí solos pueden significar un rendimiento general más bajo, tanto en indexación como en clasificación.
USA PALABRAS DESCRIPTIVAS SIEMPRE QUE PUEDAS
En vez de usar números o cifras sin significado para clasificar información, usa palabras de verdad. Por ejemplo, una URL como cocinando.com/recetas/arroz-con-pollo es muchísimo más usable y valiosa que cocinando.com/cat33/item4326.
USA GUIONES PARA SEPARAR LAS PALABRAS
No todos los buscadores saben interpretar con precisión separadores como el guión bajo “_”, el signo más “+”, o el espacio “%20”, así que usa el guión “-“para separar las palabras en una URL. Ejemplo: midominio.com/pagina-interna

URLS CANÓNICAS Y CONTENIDO DUPLICADO
El contenido duplicado es uno de los problemas más complejos que puede enfrentar cualquier web. Durante los últimos años, los buscadores han buscado y penalizado con bajos rankings a webs con contenidos pobres o copiados.
La canonicalización ocurre cuando 2 o más versiones duplicadas de una web se muestran en URLs diferentes. Esto es muy común en los sistemas de gestión de contenido modernos. Por ejemplo, cuando ofreces una versión regular de tu web y otra versión imprimible del mismo contenido. El contenido duplicado puede incluso aparecer en varias páginas web. Para los buscadores, esto presenta un problema bastante grande – qué versión de este contenido se debe mostrar a las personas? A este problema se le conoce como contenido duplicado.

Los buscadores toman muy en serio los problemas de contenido duplicado. Para brindar a las personas la mejor experiencia posible, muy pocas veces mostrarán resultados duplicados, y para esto se ven forzadas a elegir la versión del contenido que estas creen que es la original. El resultado de esto es que TODO tu contenido duplicado puede terminar con rankings mucho más bajos de lo esperado.


LA ETIQUETAS CANONICAL AL RESCATE!
Hay otra opción además de los buscadores, se llama “El Tag Canonical URL”, y es otra forma de reducir copias de un contenido duplicado en un solo sitio y canonicalizarlo en una sola URL. (También se puede usar desde una URL en un dominio a otra URL en otro diminio diferente.)
Utiliza la etiqueta canonical dentro de la página que aloja el contenido duplicado. El valor «target» de la etiqueta apuntará a la URL principal que deseas que obtenga los rankings.
ASÍ FUNCIONA INTERNAMENTE

Esto indica a los motores de búsqueda que la página en cuestión debería ser tratada como si fuera una copia de la URL seo.pe/blog y que las métricas de cualquiera de los enlaces o el contenido que los buscadores apliquen debería transmitirse de vuelta a esa URL.
El atributo del tag Canonical URL se parece en muchas cosas a un redireccionamiento 301 desde una perspectiva SEO. Básicamente, les dices a los buscadores que varias páginas deberían considerarse como una sola (que es lo que hace el 301), sin redirigir a los visitantes realmente a la nueva URL (a menudo ahorrando angustias al personal de desarrollo).


FRAGMENTOS DE TEXTO ENRIQUECIDO (RICH SNIPPETS)
¿Alguna vez has visto una valoración de 5 estrellas dentro de un resultado de búsqueda? Lo más probable es que el buscador haya recibido dicha información mediante fragmentos de texto enriquecido incrustados en la página web. Los fragmentos de texto enriquecido son un tipo de datos estructurados que permiten a los webmasters marcar su contenido en formas que brindan información extra a los motores de búsqueda.
Aunque el uso de rich snippets y de data estructurada no son un elemento obligatorio para un diseño amigable con los buscadores, su creciente adopción da a entender que los webmasters quieren obtener ventajas que puedan serles beneficiosas bajo ciertas circunstancias.
La data estructurada implica agregar marcadores a tu contenido, para que los motores de búsqueda puedan identificar fácilmente que clase de contenido es. Schema.org brinda muchos ejemplos de datos que pueden verse beneficiados con este tipo de estructura. Esto incluye información sobre personas, productos, negocios, recetas y eventos.
Con frecuencia los buscadores incluyen data estructurada en sus resultados de búsqueda, como en el caso de calificaciones de usuarios (estrellas), y perfiles de autores (fotos). Hay varias buenas fuentes para aprender más sobre los fragmentos de texto enriquecido, destacando Schema.org y la herramienta de prueba de datos estructurados de Goolge.
DEFENDIENDO EL HONOR DE TU SITIO WEB
A LOS USURPADORES LES ENCANTAN TUS RANKINGS
Desafortunadamente, la web está llena de cientos de miles (si acaso no son millones) de sitios web sin escrúpulos cuyo negocios y tráfico dependen del robo de contenidos de otros sitios web para después reusarlos (en algunos casos los modifican de formas extrañas) en sus propios dominios.
Esta práctica de obtener tu contenido y publicarlo de nuevo se llama “scraping”, y estos usurpadores llegan a ganar grandes sumas de dinero superando a los sitios web con su propio contenido y mostrando anuncios (lo irónico es que, a menudo lo hacen a través del propio programa de Google AdSense).
Cuando publiques contenido en cualquier formato de fuente – RSS / XML / etc. – asegúrate de hacer “ping” a los servicios más importantes de blogging / y rastreo (como Google, Technorati, Yahoo!, etc.). Puedes encontrar instrucciones sobre cómo hacer ping a servicios como Google y Technorati directamente en sus sitios web, o usar un servicio como Pingomatic para automatizar el proceso. Si el software que vas a publicar está personalizado, se recomienda que el desarrollador incluya el ping automático después de la edición.
A continuación, puedes usar la pereza de los usurpadores contra ellos mismos. La mayoría de los usurpadores volverán a publicar el contenido sin editarlo, y, por tanto, incluirán los enlaces de nuevo a tu sitio, y al post específico que has autorizado, así que puedes tener las seguridad de que los buscadores ven la mayoría de los enlaces de vuelta hacia ti (indicando que tu fuente es probablemente la original). Para hacer esto, necesitarás usar enlaces completos, en vez de los enlaces relativos a tu estructura de enlaces internos. Así, en vez de enlazar con tu página principal usando:
![]()
Usarías esto:
![]()
De esta manera, cuando un usurpador copia y pega el contenido, el enlace sigue apuntando hacia tu sitio web.
Hay maneras más avanzadas de protegerse contra la usurpación, pero ninguna de ellas está hecha completamente a prueba de tontos. Deberías esperar que cuanto más popular y vivible se vuelva tu sitio web, más encuentres contenido tuyo usurpado y publicado de nuevo. Muchas veces el problema se puede ignorar, pero si se vuelve muy serio, y ves que los usurpadores están quitándote los rankings y el tráfico, podrías considerar un proceso legal llamado apelación de DMCA. Afortunadamente Moz tiene una abogada que trabaja en la oficina, Sara Bird, y ha creado una gran ayuda para solucionar este problema – Cuatro maneras de hacer cumplir tu copyright: Qué hacer cuando roban tus contenidos en línea.


