Cómo los motores de búsqueda procesan los enlaces
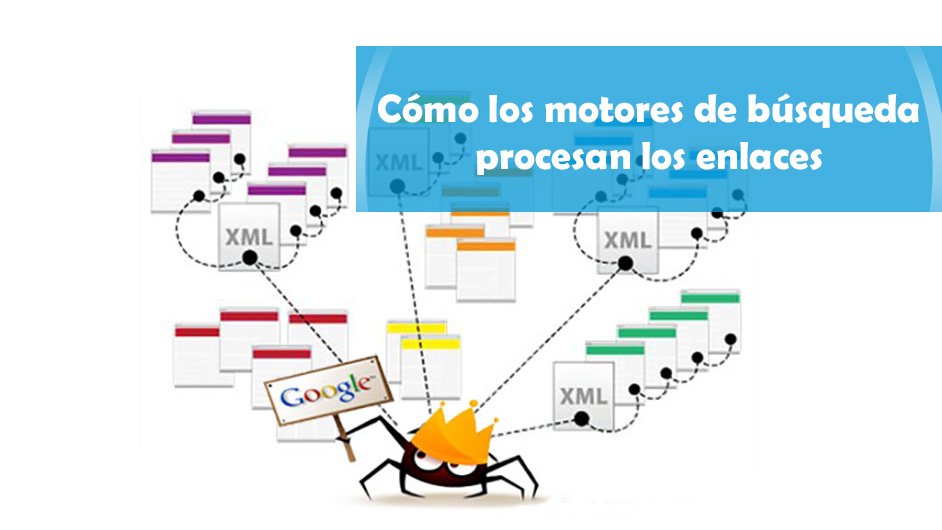
¿Alguna vez te has preguntado cómo los motores de búsqueda rastrean, analizan, indexan y clasifican las páginas? En Capybara SEO vamos a responder estas preguntas.
¿Alguna vez te has preguntado por qué 404, rel=canonical, noindex, nofollow, y robots.txt funcionan de la forma en que lo hacen? ¿Nunca has tenido claro como funcionan? Para ayudarte a entender, esta es una interpretación básica de cómo los motores de búsqueda rastrean las páginas y agregan enlaces al gráfico de enlaces.
El rastreo simple
El rastreador de los motores de búsqueda (llamémoslo araña por diversión) visita un sitio. Lo primero que recoge es el archivo robots.txt.
Asumamos que este archivo no exista o diga que está bien rastrear todo el sitio. El rastreador recopila información sobre todas esas páginas y la almacena en la base de datos. Estrictamente, es un sistema que programa rastreos que desduplica y organiza las páginas por prioridad para luego indexarlas.
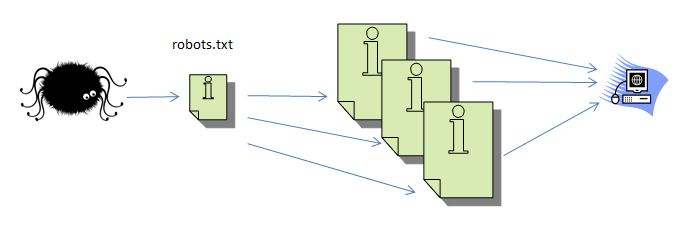
Mientras está ahí, recopila una lista de todas las páginas a la que se enlaza cada página. Si son enlaces internos, el rastreador probablemente los seguirá a otras páginas. Si son externos, los coloca en la base de datos.
Procesamiento de enlaces
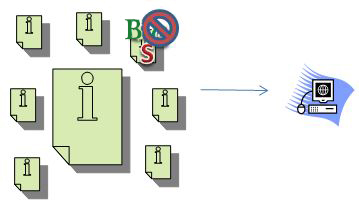
Luego, cuando se procesa el gráfico de enlaces, el motor de búsqueda extrae los enlaces de la base de datos y luego los conecta al asignarles valores relativos. Los valores pueden ser positivos o pueden ser negativos. Por ejemplo, imaginemos que una de esas páginas es spam. Si esa página enlaza a otras páginas, entonces puede pasar malos valores de enlace a esas páginas. Digamos que S = Spam y B = Bueno:
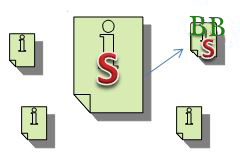
La página de la parte superior derecha tiene más B que S. En consecuencia, obtendría una puntuación aceptable. Una página con solo B obtendría un mejor puntaje. Si las S superan a las B, entonces la página obtendría un puntaje pobre. Agreguemos a esto la complicación de que algunas S y B valen más que otras. Aquí solo haremos un repaso muy simplificado de cómo funcionan los gráficos de enlace.
Bloqueo de páginas con robots.txt
Retrocedamos al ejemplo original. Supongamos que el archivo robots.txt haya dicho al buscador que no acceda a una de esas páginas.
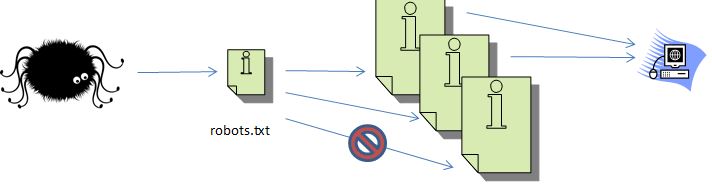
Esto significa que mientras que el motor de búsqueda rastrea las páginas y hace listas de los enlaces, no tendría ninguna información sobre la página que incluyó el archivo robots.txt.
Ahora, volvamos al ejemplo supersimple del gráfico de enlaces. Supongamos que la página superior derecha es la página bloqueada por robots.txt.
El motor de búsqueda de todas maneras recopilará todos los enlaces que dirigen hacia esa página y los contará. Sin embargo, no podrá ver a qué páginas enlaza esa página, pero podrá agregarle métricas de valor de enlace —que afecta al dominio como un todo.
Utiliza 404 o 410 para eliminar páginas
Ahora, asumamos que en lugar de bloquear una página con robots.txt, simplemente la eliminamos. Entonces, el motor de búsqueda intentará entrar en ella, pero leerá un claro mensaje que ya no está más ahí.
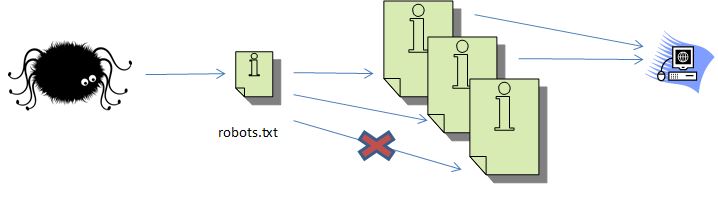
Esto significa que cuando se procesa un gráfico de enlaces, los enlaces a esa página desaparecen. La página se almacena por si luego deciden reutilizarla.
En algún otro punto (y tal vez por otros servidores) las páginas prioritarias que se rastrean son asignadas a un índice.
Cómo funciona el índice
El motor de búsqueda identifica palabras y elementos en una página que coincidan con palabras y elementos en la base de datos. Haz una búsqueda para «dispositivos azules». El motor de búsqueda utiliza la base de datos para encontrar páginas relacionadas con el azul, con dispositivos y con dispositivos azules. Si el motor de búsqueda también considera como sinónimos dispositivo (singular) y aciano (un tipo de azul), también puede evaluar páginas con esas palabras.
El motor de búsqueda utiliza su algoritmo para determinar qué paginas en el índice tienen esas palabras asignadas, evalúa los enlaces que se dirigen a la página y al domino y procesa docenas de otras métricas conocidas y desconocidas para llegar al valor. También se toma en cuenta si el sitio se filtra por tener un pobre comportamiento, como Panda y Penguin. Entonces, el valor general determina en que parte de los resultados aparecerá la página.
Esto se complica más por cosas que los webmasters hacen para manipular los valores. Por ejemplo, si dos páginas son muy similares, un webmaster puede decidir utilizar rel=canonical para señalar al motor de búsqueda que solo una de esas páginas tiene valor, aunque esto no es definitivo. Si en la página «dispositivo aciano» se utiliza rel=canonical para la página «dispositivos azules», pero el dispositivo aciano tiene más enlaces valiosos, en motor de búsqueda puede elegir utilizar la página dispositivo aciano. Si se acepta el canónico, los valores de ambos elementos en las páginas y los enlaces que dirigen a esas páginas pueden ser combinados.
Eliminar páginas con noindex
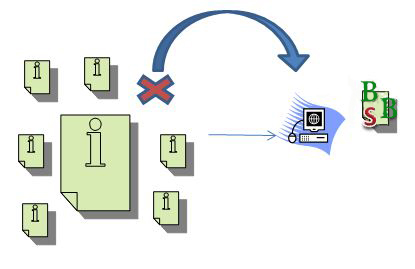
Noindex es más definitivo. Funciona de forma similar que robots.txt, pero en vez de evitar que se rastree la página, el motor de búsqueda puede acceder a ella y luego se le dice que se vaya. El motor de búsqueda recopilará los enlaces en la página y las agregará en la base de datos (a menos que una orden en la página indique no seguirlos. Ejemplo: nofollow) y agregará valor a los enlaces que apuntan a esa página.
Sin embargo, no agregará valor a ninguna otra página y no detendrá el valor que fluye por la página. Todo lo que hace el noindex es pedir al motor de búsqueda que no agregue la página a su índice.
En consecuencia, solo hay una forma definitiva de detener el flujo del valor del enlace en el destino. Eliminar la página de forma completa (códigos de estado 404 o 410) es la única forma de detenerlo. El código 410 es más definitivo que el 404, pero ambos provocarán que, eventualmente, la página deje del índice. Existen múltiples formas de detener el flujo de enlaces desde el origen del enlace, pero los webmasters, raras veces, tienen control sobre los otros sitios, sólo su propio sitio.
Es muy importante saber cómo controlar el flujo de visitas de Google hacia nuestra página web. No es de conocimiento común saber que podemos indicarle a Google qué secciones de nuestra página puede indexar, o debe dejar de indexar, ni cómo es posible hacerlo. Un consultor en posicionamiento en buscadores es indispensable para atender estos asuntos y asegurarnos de que nuestra página web aparezca de la mejor forma posible en los motores de búsqueda.
Esperamos que esta guía básica les haya ayudado a entender cómo los motores de búsquedas procesas las páginas y la diferencia entre robots.txt, noindex, y no encontrado (404), en especial como se relacionan con los enlaces.
Deja cualquier pregunta en la sección comentarios, en Capybara SEO estaremos contentos de responderte.


